

Mistral AI vs LLaMA is a question I keep hearing from builders, students, and small teams who want powerful AI without being locked into one platform. And I get it. Open-source models feel like freedom. You can run them where you want, tune them how you want, and control your data better. Still, the choice is not always simple, because “better” depends on your goal.
In my view, Mistral AI vs LLaMA is not a fight where one model destroys the other. It’s more like choosing between two strong toolkits. One might feel faster on your hardware. Another might feel easier to deploy in your setup. Also, your use case matters a lot: chatbot, coding helper, knowledge bot, or local private assistant.
In this guide, I’ll explain Mistral AI vs LLaMA in plain language. I’ll compare what matters in real life—speed, quality, cost, memory, fine-tuning, and practical use cases. I’ll also share my honest opinion, give ratings, include a comparison table, and answer common questions. ✅
I tested small models. I tested bigger models. I tested the same prompts again and again.
Then I noticed something important: “best” changes based on your constraints.
After that, I stopped looking for one winner for everyone.
What Open-Source Model Means (Simple Explanation) 🔓
Before we jump deeper into Mistral AI vs LLaMA, let’s clear one thing up.
An open-source model usually means:
- you can download weights (depending on license)
- you can run it on your own machine or server
- you can fine-tune it
- you can control data and privacy more
For me indicates one big benefit: control. You can build a product without depending fully on a hosted chatbot.
Quick Overview: What Mistral AI and LLaMA Are 🧠
Mistral AI (in simple words)
Mistral models are known for being efficient and strong for their size. I often hear people choose them when they want good performance without massive hardware.
LLaMA (in simple words)
LLaMA models are widely used and have a huge community. Many tools, guides, and fine-tunes exist around them, which makes building easier.
So Mistral AI vs LLaMA often feels like:
- efficiency and speed focus vs wide ecosystem and support
Mistral AI vs LLaMA: The Real Question I Ask First 🎯
When someone asks me “Mistral AI vs LLaMA,” I ask this first:
Where will you run it?
Because hardware decides everything:
- If you run locally on a laptop, you need smaller models.
- If you run on a GPU server, you can handle larger ones.
- If you run on CPU only, speed and quantization matter a lot.
So in Mistral AI vs LLaMA, “better” depends on your hardware and latency goals.
Performance and Speed: Mistral AI vs LLaMA ⚡
Speed matters because a slow bot feels broken.
What I notice in real use
In many setups, Mistral-style models can feel fast and efficient for their size. LLaMA models can also be fast, but the experience depends heavily on:
- the model size you pick
- the quantization level
- your GPU memory
- your serving stack
My simple takeaway:
Mistral AI vs LLaMA for speed is often a hardware story, not only a model story.
Output Quality: How “Smart” Do They Feel? 🧠✨
People say “smart” when they mean:
- does it follow instructions
- does it stay consistent
- does it answer clearly
- does it avoid weird mistakes
Mistral AI vs LLaMA for clarity
In my experience, both can be very strong. The biggest difference comes from the specific model variant and how you prompt it.
What helps quality more than the brand name:
- good system prompt
- clean formatting
- short, direct instructions
- examples of the style you want
So, I don’t treat Mistral AI vs LLaMA as a simple IQ test. I treat it like “which one fits my workflow.”
Context Length: How Much Can They Remember? 🧾
Context length is how much text the model can consider at once (your prompt + history + documents).
For real projects like:
- document Q&A
- long chats
- knowledge assistants
…context length matters.
In Mistral AI vs LLaMA, both ecosystems offer options that support longer contexts (depending on the specific model you choose). But practical context is not only the number. It’s also:
- how well the model uses that context
- whether it stays focused
- whether it ignores key details
My advice: test with your real documents. Marketing numbers don’t always match real behavior.
Fine-Tuning and Custom Training: Mistral AI vs LLaMA 🛠️
If you want the model to sound like your brand, follow your rules, or handle a special domain, you may fine-tune.
LLaMA advantage: ecosystem
LLaMA has a massive community. That often means:
- more tutorials
- more example configs
- more community fine-tunes
- more integration guides
Mistral advantage: efficiency mindset
Mistral-based models often attract builders who care about:
- smaller hardware
- faster inference
- strong results per parameter
So Mistral AI vs LLaMA for fine-tuning often becomes:
- “Do I want the easiest community path?” → LLaMA
- “Do I want efficiency-first builds?” → Mistral
Safety and Control: What Happens When Users Push It? 🛡️
Safety is tricky in open-source. Some models are more “guardrailed,” while others are more open.
In Mistral AI vs LLaMA, your safety level often depends on:
- the base model vs instruction model you pick
- your system prompt
- your content filtering layer
- your product rules
My view: open-source gives freedom, but it also gives responsibility. If you’re building a public app, you need:
- moderation
- logging
- rate limits
- clear policy messages
That matters more than arguing Mistral AI vs LLaMA online.
Cost: What You Pay in Real Life 💸
With open-source models, you “pay” in different ways:
- GPU cost (renting or buying)
- engineering time
- optimization time
- monitoring and maintenance
What I personally see
- Smaller, efficient models can reduce cost.
- Bigger models can improve quality but raise cost.
- Bad prompts and poor caching can waste money quickly.
So, Mistral AI vs LLaMA cost is not just “free vs paid.” It’s about compute and time.
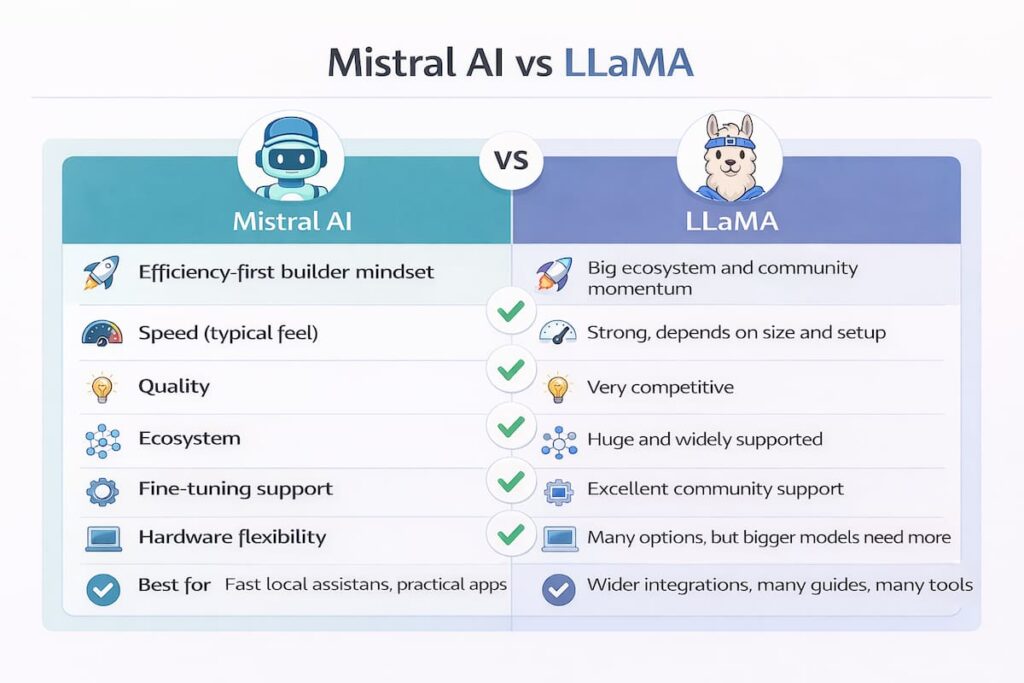
Comparison Table: Mistral AI vs LLaMA 📊
| Category | Mistral side | LLaMA side |
|---|---|---|
| Best vibe | Efficiency-first builder mindset | Big ecosystem and community momentum |
| Speed (typical feel) | Often strong for size | Strong, depends on size and setup |
| Quality | Very competitive | Very competitive |
| Ecosystem | Growing fast | Huge and widely supported |
| Fine-tuning support | Good | Excellent community support |
| Hardware flexibility | Often friendly to smaller setups | Many options, but bigger models need more |
| Best for | Fast local assistants, practical apps | Wider integrations, many guides, many tools |
This table is my simplest way to explain Mistral AI vs LLaMA without overcomplicating it.
Use Cases: Which One I’d Pick and Why ✅
1) Local private assistant (offline-ish) 🧑💻
If I’m running locally and care about speed, I often lean Mistral-style efficient models. But I still test a similar-sized LLaMA variant, because surprises happen.
2) Startup chatbot for a product 💬
For a product bot, I care about reliability and tooling. I often lean LLaMA because the ecosystem makes shipping easier. Still, Mistral options can be excellent when you want speed and cost control.
3) Document Q&A (RAG) 📚
For RAG systems, the model is only one part. Retrieval quality matters a lot. In Mistral AI vs LLaMA for RAG, I pick the one that:
- follows instructions best
- stays grounded in the provided text
- handles citations/formatting cleanly (if you need it)
4) Coding helper 👨💻
Both families can work. I focus on:
- instruction following
- correctness
- how it handles errors
- how often it hallucinates code
Again, I test both because “best” depends on your prompt and stack.
My Opinion: Mistral AI vs LLaMA (Not Biased) 🗣️
Here’s my honest opinion.
If I want the easiest path to build and ship, I lean LLaMA more often. The ecosystem is a real advantage. You can find guides, tools, and community help quickly. When you’re building fast, that support matters.
If I want strong results on limited hardware, I lean Mistral more often. Efficient models feel great when you’re trying to run locally, reduce cost, or keep latency low. That practical efficiency is a real win.
So for me, Mistral AI vs LLaMA comes down to this:
- LLaMA when I value ecosystem and “easier to integrate”
- Mistral when I value efficiency and “better on tight hardware”
I don’t think one is always better. I think one is better for your current constraints.
Ratings: Mistral AI vs LLaMA ⭐
These ratings are based on how I think most builders experience them in real projects (not lab benchmarks). Scores are out of 10.
Mistral ratings ⭐
- Efficiency / performance per size: 9.2/10
- Speed and latency feel: 8.8/10
- Quality for general tasks: 8.7/10
- Ease of deployment (average): 8.2/10
- Community breadth: 7.9/10
- Overall: 8.6/10
LLaMA ratings ⭐
- Efficiency / performance per size: 8.6/10
- Speed and latency feel: 8.5/10
- Quality for general tasks: 8.8/10
- Ease of deployment (average): 8.7/10
- Community breadth: 9.4/10
- Overall: 8.8/10
Notice how close they are. That’s exactly why Mistral AI vs LLaMA is more about fit than dominance.
How I’d Choose in 60 Seconds ⏱️
If you want a quick decision, I use this checklist:
Choose Mistral if:
- you want speed on smaller hardware
- you care a lot about cost and latency
- you like practical, efficient builds
Choose LLaMA if:
- you want maximum community support
- you want lots of tools and integrations
- you want many fine-tunes and examples
If you can, test both with one real task. That’s the fastest truth.
Practical Tips to Get Better Results (Works for Both) 🧩✨
No matter what you choose in Mistral AI vs LLaMA, these tips improve output:
- Use clear instructions with short sentences
- Provide an example of the format you want
- Keep system prompts simple, not huge
- Ask for step-by-step only when needed
- Add a “don’t hallucinate” rule like: “If unsure, say you’re unsure”
- For RAG, paste only the most relevant chunks, not everything
Also, I always add a final step:
- “Now summarize your answer in 5 bullet points.”
That makes responses easier to use.
FAQ: Mistral AI vs LLaMA ❓
1) Mistral AI vs LLaMA: which open-source model is better overall?
For me, it’s very close. LLaMA often wins on ecosystem and support. Mistral often wins on efficiency for its size. The best choice depends on your hardware, budget, and project goals.
2) Is Mistral AI vs LLaMA better for running locally?
If you’re running locally on limited hardware, I often lean Mistral-style efficiency. Still, a similar-sized LLaMA model can also work well. Testing both is the smartest move.
3) Which is easier to fine-tune?
Both can be fine-tuned, but LLaMA often feels easier because of the huge number of tutorials, community tools, and examples. That ecosystem advantage matters a lot.
4) Which is better for RAG and document chatbots?
In Mistral AI vs LLaMA for RAG, retrieval quality and prompt format matter as much as the model. I choose the model that follows instructions well and stays grounded in the provided text.
5) Do I need a GPU for Mistral AI vs LLaMA?
A GPU helps a lot for speed, especially with larger models. Some smaller models can run on CPU with quantization, but latency can become an issue for interactive chat.
6) Which one should a beginner choose?
If you’re a beginner and want guides and community help, LLaMA is often the easier starting point. If you’re optimizing for local speed and efficiency, Mistral can be very satisfying.